Last Updated on September 22, 2023 by KnownSense
Autonomy in microservices refers to the degree of independence and self-sufficiency that each individual microservice possesses within a microservices architecture. This enhances the performance and reliability of the service and gives consumers more guarantees about the quality of service they can expect from it. Coupled with statelessness, autonomy also contributes to the overall availability and scalability of the service. With increased autonomy, the microservices architecture is less likely to experience failures or performance issues because of another microservice.
Ways to create Autonomous services
Now we will learn how we can make our microservices autonomous so that each service is independently changeable and deployable without affecting any other parts of our system in a negative way.
1. Loose Coupling
One of the key design approaches for this is loose coupling where we make sure each one of our microservices is independent from other services because they have limited knowledge about the inner workings, i.e. the code, within other services. The easiest way of achieving this is by having our microservices physically separate from each other by having them communicate with each other using the network and by using proven open network communication protocols like HTTP.

So just like when we’re using our mobile phones to browse the internet, using networks and HTTP, our upstream clients and our upstream services don’t need to know too much detail, i.e. the inner workings, of our downstream services that are providing all the data and functionality. And we especially don’t want our upstream client applications and our services to have special code or client libraries provided by our downstream service in order to talk to our downstream microservice because this will mean any changes to our downstream microservice might mean there are changes to the client library that our upstream services are using, and therefore, it will force our upstream services to also change when our downstream services change.
Luckily for us, open communication protocols like HTTP allow us to talk to downstream services without having to have any special code. Instead, we use normal standard web requests.
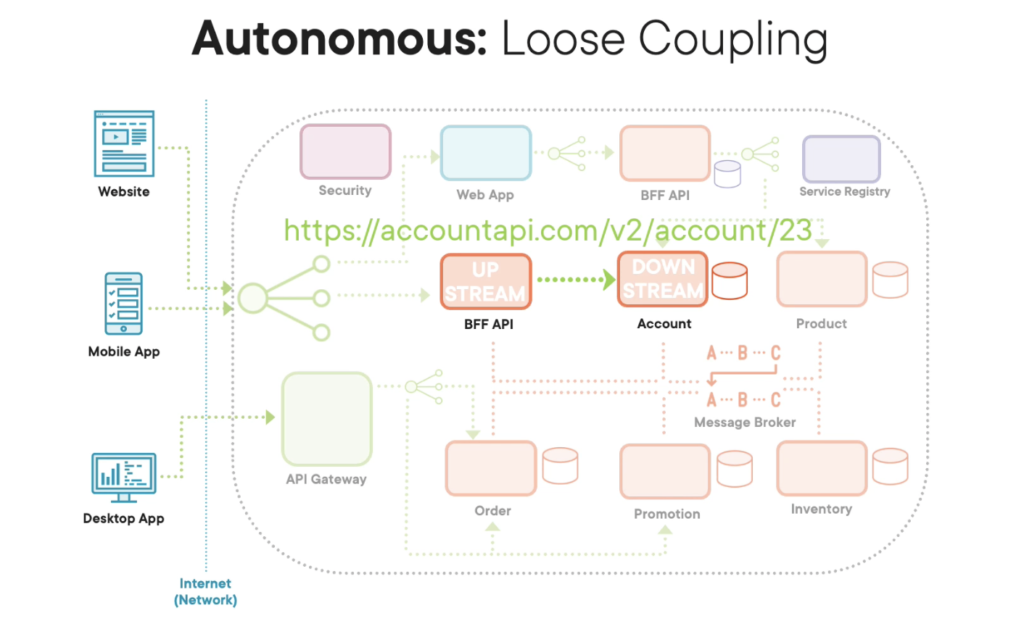
To further loosely couple our services, we need to ensure that when we do HTTP calls, we make the minimal amount of calls required in order to fetch data or to carry out a functionality with our downstream service instead of having chatty exchanges where we’re having to make multiple calls in order to fetch that one piece of data or to carry out that one piece of functionality. Chatty exchanges between applications is basically a sign that they are tightly coupled, i.e. they are intertwined. So if our downstream service changes, it’s likely that our upstream service will also likely have to change.
Also to make sure our microservices loosely coupled we need to ensure that they have their own data. They have their own dedicated database that’s not shared with any other microservice, and the only way to get each microservice’s data is to talk to the microservice itself.
2. Contracts and Interfaces
Another way of making sure our microservices are autonomous is by ensuring that calls that we’re making between our services, have stable requests and responses. These HTTP calls requests and responses remain stable even if our microservices themselves are changing. The format of these calls, are commonly referred to as the contract and the interfaces between our microservices. We always want to try and honor these contract and interfaces in terms of request format and response format so that when we change a specific microservice, any other client application or any other service calling that microservice doesn’t have to change.
The same applies to microservices that are talking to each other using asynchronous communication using components like a message broker, where contracts are the number of messages exchanged and the interface is the format of the message itself. We want to keep the format of the messages stable regardless of our microservices changing themselves.
Small changes, however, can sometimes be okay where we’re adding extra data. However, we should try and avoid breaking changes where the format of the data has changed or if we’ve omitted data. We should always try and honor our contracts and interfaces whilst we’re changing parts of our architecture.

Another way of making our contracts more stable and our microservices more autonomous is by making sure that we expose the minimal amount of data from our microservices. So if there’s any extra data that’s used within the inner workings of the microservice, only expose part of the data that’s actually required by the outside world of that microservice, and any inner working data you keep internally.
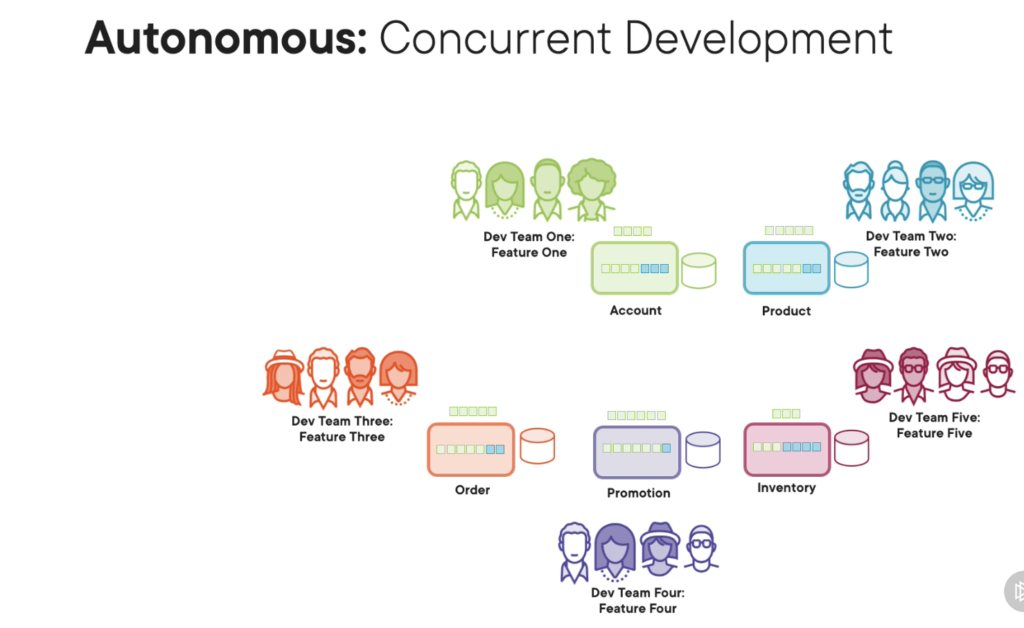
3. Concurrent Development
Another way of making our microservices more autonomous with stable contract is by having specific teams own specific microservices. Not only will this encourage concurrent development, but it will force our teams to work in a collaborative way in order to agree and discuss contract for each of their microservices exposes to other microservices.
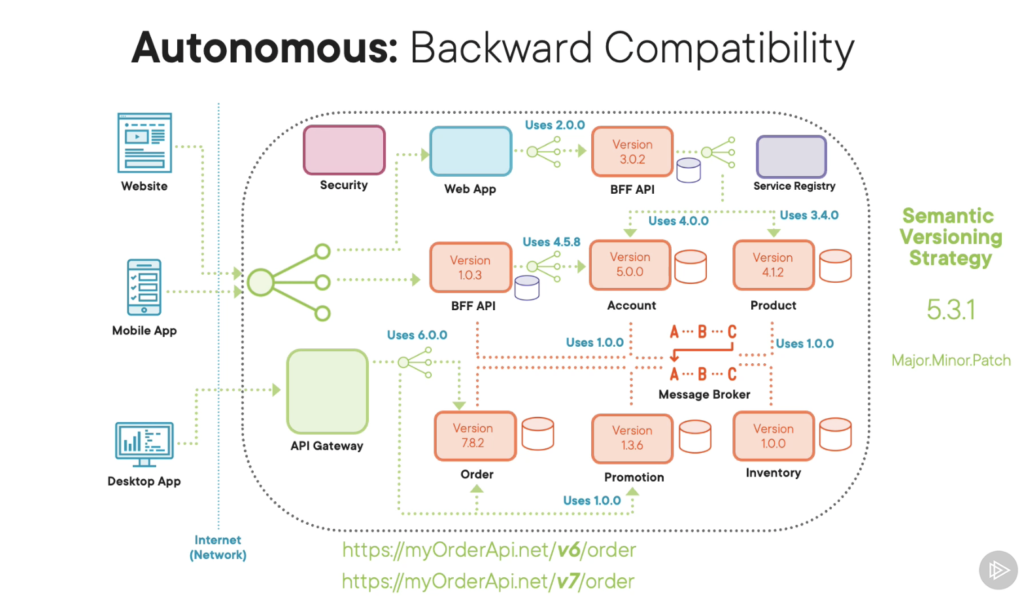
4. Backwards Compatibility
If there are breaking changes, it will also force other teams to work together to ensure that there’s backwards compatibility. And having backward compatible microservices basically means when we release new versions of our microservices with the contracts that potentially have breaking changes, our client applications or client services, that user‑changed microservices, are not affected because our microservices are backward compatible in that they still support and provide the older versions of the contracts and interfaces. So that means our upstream clients and services that are consuming a change to downstream microservices don’t have to actually change.
So the first thing you need as part of your microservices’ backwards compatibility strategy is to have a versioning strategy for your microservices to communicate what kind of change you’ve made to that microservice. A really good versioning strategy for this is known as semantic versioning strategy, which basically uses three digits to communicate if you’ve made a breaking change to your microservice, where the consumers of that microservice will have to change, or if you’ve made a change that’s compatible with all existing consumers. But the key part of your backwards compatibility strategy is for your microservices to have the ability to support both the old functionality, the old contracts and interfaces, as well as the new changed contracts and interfaces, as well as the functionality and data. The good news is this is quite easily achievable when we’re using microservices which are HTTP‑based APIs. We can easily have duplicate endpoints which are separated by version numbers.
For example version 6 might provide the old functionality, which is compatible with most of your consumers, and you might have a new version of that endpoint with version 7, which provides that breaking change. And the same applies to microservices that listen out for messages on a message broker. Our microservices can easily support multiple versions of a specific functionality. In the message broker case, we can check the message to see what version we’re actually targeting, and then within our microservice, we can easily process that message using that specific version of the code.
5. Stateless
Another key design approach in order to achieve autonomous microservices is to have microservices instances that are stateless in that they don’t have any in‑memory data that’s required to process related requests. I should basically have the ability to replace any one of my microservices without having to worry about what’s actually in the memory of each one of those microservice instances. If you do need state data, the best way to do this is to include extra information within your request, like, for example, IDs that can be used to pull out extra data out of the databases that the microservices own.
6. Conceptual Microservice
Another thing worth mentioning was we’re talking about how to make our microservices independently changeable and deployable, is that our microservices might not be a single application. Our microservices might be a conceptual microservice which actually includes multiple applications. So, for example, it might feature an application which is the HTTP API part of your conceptual microservice, but there might also be another application as part of that conceptual microservice which is responsible for listening out for messages from a message queue from a message broker. But the key thing is the idea is the same. Your conceptual microservice should be independently changeable and deployable. It should have its own database that’s only accessible by the apps within that conceptual microservice, and it’s a database that’s not directly shared with anything else.

However, it’s essential to strike a balance between autonomy and coordination in a microservices architecture. While autonomy is critical for development speed and independence, there must be mechanisms in place for communication, integration, monitoring, and governance to ensure that the overall system functions cohesively and meets business objectives. Properly managing the trade-offs between autonomy and coordination is key to the success of a microservices-based application.
Conclusion
In summary, autonomy is a vital microservices principle that empowers teams and services to operate independently, but it must be complemented by robust practices and tools that promote collaboration, consistency, and overall system integrity in a microservices environment. When implemented correctly, autonomy can significantly contribute to the success of a microservices-based application.