Last Updated on September 14, 2023 by KnownSense
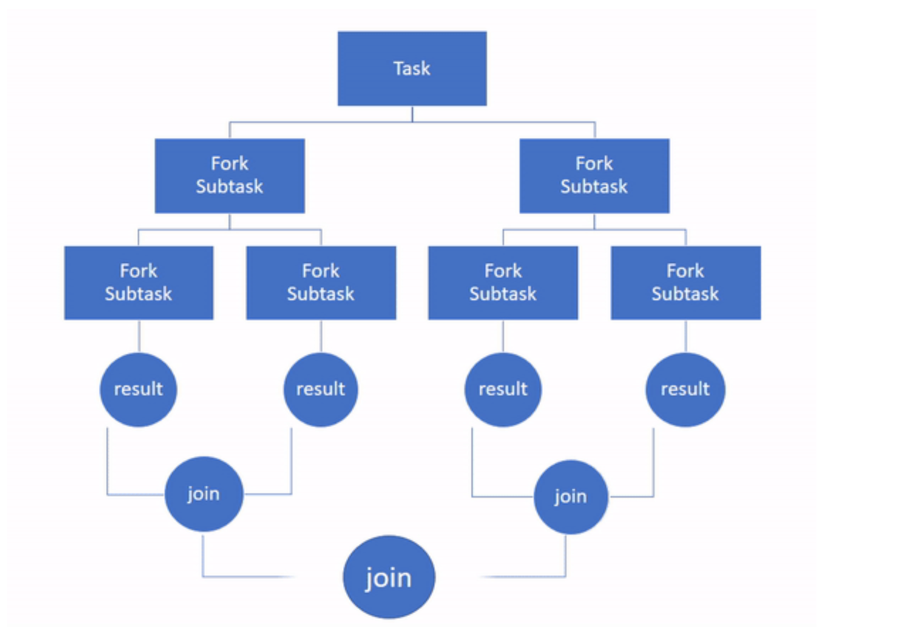
Java 7 introduced the fork/join framework. It is among the simplest and most effective design techniques for obtaining good parallel performance. Fork/join algorithms are parallel versions of familiar divide−and−conquer algorithms.
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
The fork operation starts a new parallel fork/join subtask. The join operation causes the current task not to proceed until the forked subtask has completed. Fork/join algorithms, like other divide−and−conquer algorithms, are nearly always recursive, repeatedly splitting subtasks until they are small enough to solve using simple, short sequential methods.
Understanding the framework classes
The fork/join framework has two main classes, ForkJoinPool and ForkJoinTask.
ForkJoinPool is an implementation of the interface ExecutorService. In general, executors provide an easier way to manage concurrent tasks than plain old threads. The main feature of this implementation is the work-stealing algorithm. There’s a common ForkJoinPool instance available to all applications that you can get with the static method commonPool()
ForkJoinPool commonPool = ForkJoinPool.commonPool();The common pool is used by any task that is not explicitly submitted to a specific pool, like the ones used by parallel streams. Using the common pool normally reduces resource usage because its threads are slowly reclaimed during periods of non-use, and reinstated upon subsequent use.
You can also create your own ForkJoinPool instance using one of these constructors
ForkJoinPool()
ForkJoinPool(int parallelism)
ForkJoinPool(int parallelism, ForkJoinPool.ForkJoinWorkerThreadFactory factory, Thread.UncaughtExceptionHandler handler, boolean asyncMode)ForkJoinPool class invokes a task of type ForkJoinTask, which you have to implement by extending one of its two subclasses:
– RecursiveAction: which represents tasks that do not yield a return value, like a Runnable.
– RecursiveTask: which represents tasks that yield return values, like a Callable.
ForkJoinTask subclasses also contain the following methods:
- fork(): which allows a ForkJoinTask to be scheduled for asynchronous execution (launching a new subtask from an existing one).
- join(): which returns the result of the computation when it is done,allowing a task to wait for the completion of another one.
Steps of execution
- First, you have to decide when the problem is small enough to solve directly. This acts as the base case. A big task is divided into smaller tasks recursively until the base case is reached.
- Each time a task is divided, you call the
fork()method to place the first subtask in the current thread’s deque, and then you call thecompute()method on the second subtask to recursively process it. - Finally, to get the result of the first subtask you call the
join()method on this first subtask. This should be the last step becausejoin()will block the next program from being processed until the result is returned. - Thus, the order in which you call the methods is important. If you don’t call
fork()beforejoin(), there won’t be any result to retrieve. If you calljoin()beforecompute(), the program will perform like if it was executed in one thread and you’ll be wasting time. - If you follow the right order, while the second subtask is recursively calculating the value, the first one can be stolen by another thread to process it. This way, when
join()is finally called, either the result is ready or you don’t have to wait a long time to get it. - You can also call the method invokeAll(ForkJoinTask<?>… tasks) to fork and join the task in the right order
Implementation with RecursiveAction Interface
public class Sum extends RecursiveAction {
private static final int SEQUENTIAL_THRESHOLD = 5;
private List<Long> data;
public Sum(List<Long> data) {
this.data = data;
}
private long computeSumDirectly() {
long sum = 0;
for (Long l: data) {
sum += l;
}
return sum;
}
@Override
protected void compute() {
if (data.size() <= SEQUENTIAL_THRESHOLD) { // base case
long sum = computeSumDirectly();
System.out.format("Sum of %s: %d\n", data.toString(), sum);
} else { // recursive case
// Calcuate new range
int mid = data.size() / 2;
Sum firstSubtask =
new Sum(data.subList(0, mid));
Sum secondSubtask =
new Sum(data.subList(mid, data.size()));
firstSubtask.fork(); // queue the first task
secondSubtask.compute(); // compute the second task
firstSubtask.join(); // wait for the first task result
// Or simply call
//invokeAll(firstSubtask, secondSubtask);
}
}
public static void main(String[] args) {
Random random = new Random();
List<Long> data = random
.longs(20, 1, 5)
.boxed()
.collect(toList());
ForkJoinPool pool = new ForkJoinPool();
Sum task = new Sum(data);
pool.invoke(task);
}
}